TANGERINE FOCUS
a lens for looking at models

A progression is underway.

V1.0 Drawings in Mental Models
Drawing is a lens for looking. It’s the vehicle for looking with intent — at models mental, physical, and digital — and showing that you did.
From the first time anyone scratched out a drawing on a cave wall, they instantiated the graphic where it is in-situ within the mental model in formation in their mind. An interplay was underway.

V2.0 Drawing-Model Fusion (2012)
I invented the automatic fusion of drawings in digital models in 2012. See the story here: Drawing-Model Fusion 2012
Fusion, …like recorded sound in (formerly) silent film.
With the popularization of digital modeling by the 1990s, technical drawing continued in its usual role while instantiation into the model remained unaltered since the time of cave painting (V1.0), done by mental exercise alone, unassisted by the digital model.

(OPEN VCS) V3.0
Using digital models to evolve the form
of expression, of the vehicle for looking with intent — at models mental, physical, and digital — and showing that you did.
Not only a fusion, but an evolution in form that surfaces the best of both media (model and drawing), in a new form of expression greater than the sum of its parts.
Going the wrong way for 35+ years
Paul Burchard, PhD says philosophy precedes both science and engineering.
An old friend said it also precedes philosophers getting tied to the whipping post.
To earn the whipping I’ve written this blog since 2016 (and did my earlier work since 2007) to counter absurd notions and convey what I know first hand from doing AEC modeling and drawing myself.
To get on target, what makes a difference is:
To ask what drawings are:
a lens for looking with intent — at models mental, physical, and digital — and showing that you did.
To know that drawings are not “just dumb lines and arcs”.
They facilitate the core work of AEC professions; they’re a medium for thinking things through all the way through.
To imagine using digital models to evolve the form of expression of the lens for looking:
If technical drawing were invented today in the midst of digital modeling instead of centuries ago, what would it look like?
Absurd notions—about the demise of technical drawing in architecture, engineering, and construction, and advocacy for this demise—trample over discourse since 2004
The situation is stagnant.
Drawing is not being replaced and isn’t replaceable by models. The idea is like “replacing” telescopes with the cosmos. We have the universe in the night sky, therefore we should rid ourselves of our lens for looking at it, abandon our telescopes. Countering this, one argues against utter nonsense (and its entrenched believers)
Drawing quality has declined though over the last 20 years, typically, accompanied by inadequate digital modeling. We’re dealing with demise but of a higher order, not of drawing but of things greater.
Discussion needs to return to fundamentals.
Start again by understanding what drawing is
as was well known in former times.
Software development will follow.
Looking (seeing) and thinking are a loop
I say:
Drawing is a lens for looking with intent—at models mental, physical, and digital—and showing that you did.
But what does that mean?
And in any case, one cannot just assert; the meaning has to be discussed.
Judge for yourself if the assertion is supported:
What is the intent?
The answer has two components:
1. Notice the loop:
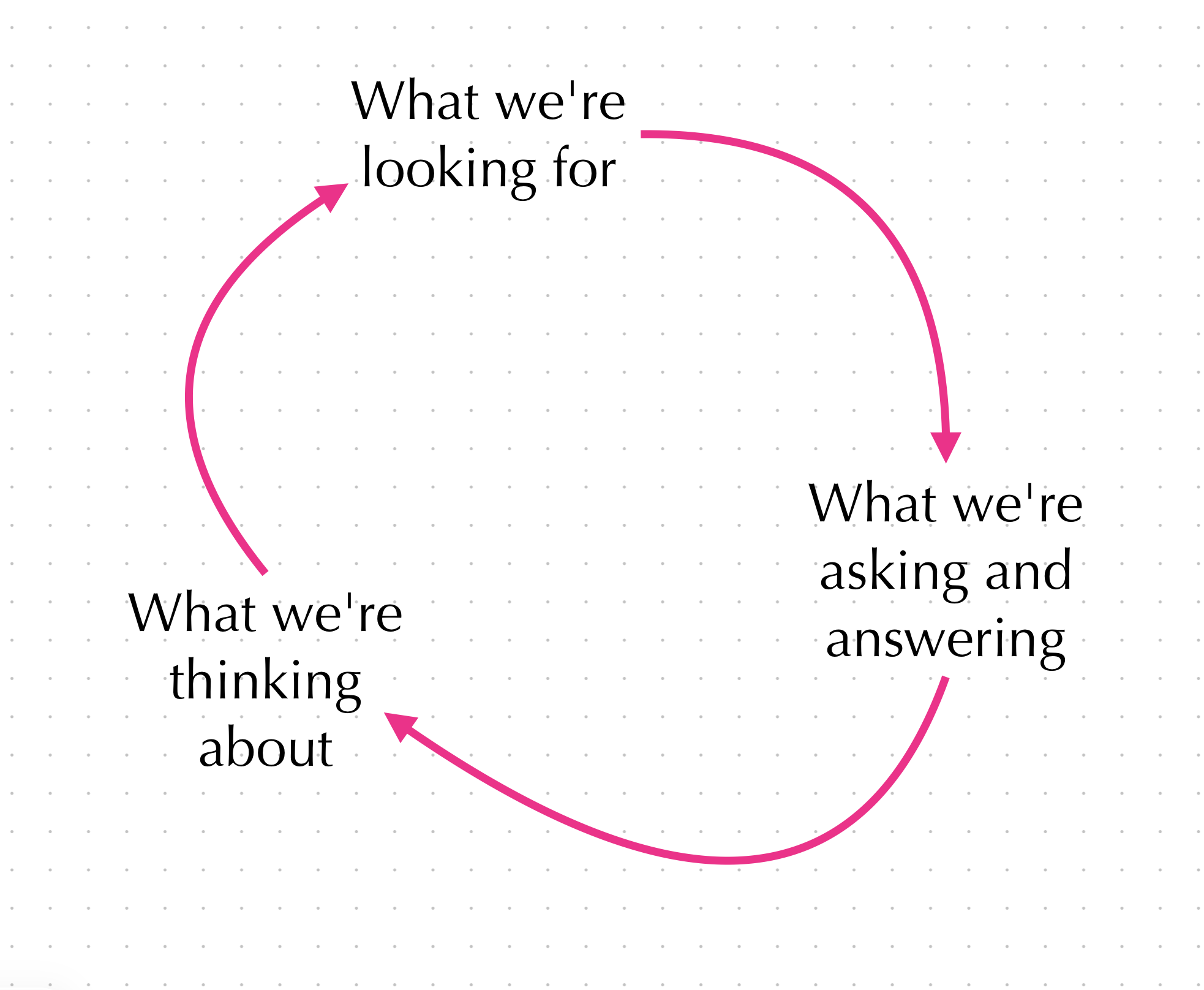
2. And note the intent, told on the black field below (please read it)::
It’s the what(s) and why, why we draw:
- what we’re looking for (and at)
- what we’re asking and answering
- what we’re thinking about (and how we think)
- and why we do this, why we draw
- it’s to gather all of these whats
- all together it’s the intent:

The intent really is about getting ourselves into this loop.
- What we see and look at informs what we think about.
- What we think about informs what we see and look at.


The set of drawings is the expression of this loop, both the active experience of it, and a tangible record of it.
The idea of dispensing with that is self-defeating and counterproductive. Like abandoning telescopes, It’s also like refusing to believe that recorded sound ought to be infused (synchronized) into silent film. Many did refuse that including Jack Warner himself in 1926 even 28 years after the first machine demonstrating the fusion of sound into film in 1898:
In September 1926, Jack L. Warner, head of Warner Bros., was quoted to the effect that talking pictures would never be viable: “They fail to take into account the international language of the silent pictures, and the unconscious share of each onlooker in creating the play, the action, the plot, and the imagined dialogue for himself.”[146]
Inevitably though, AEC has not dispensed with the vehicle for looking at models, drawing.
But what the software industry has done is this:
They’ve locked the vehicle for looking with intent at models into a form of expression that predates digital modeling (and digital computing) by centuries.
The vehicle for:
- looking with intent at digital models and showing that you did,
looks and feels exactly like the vehicle for:
- looking with intent at mental models and showing that you did.
21st century software does nothing to develop the form of the vehicle.
On the contrary, it appears as if designed to enforce stasis and prevent development.
This is mostly unwitting because it just never occurs to developers of these products to ask:
What—are—drawings?
- A lens for looking with intent — at models mental, physical, and digital — and showing that you did.
Why not use digital models to evolve the form of expression of the lens for looking?
If technical drawing were invented in the midst of digital modeling today instead of centuries ago, what would it look like?
Unlock the vehicle:
https://tangerinefocus.com
Some steps have been taken.
See block [2] below.
The steps have not reached the core apps, yet.
And the steps already taken are just a baby’s first steps.
See block [3] below for what mature athletic steps would look like if taken:
Progress is certain:

V1.0 Drawings in Mental Models
Drawing is a lens for looking. It’s the vehicle for looking with intent — at models mental, physical, and digital — and showing that you did.
From the first time anyone scratched out a drawing on a cave wall, they instantiated the graphic where it is in-situ within the mental model in formation in their mind. An interplay was underway.

V2.0 Drawing-Model Fusion (2012)
I invented the automatic fusion of drawings in digital models in 2012. See the story here: Drawing-Model Fusion 2012
Fusion, …like recorded sound in (formerly) silent film.
With the popularization of digital modeling by the 1990s, technical drawing continued in its usual role while instantiation into the model remained unaltered since the time of cave painting (V1.0), done by mental exercise alone, unassisted by the digital model.

(OPEN VCS) V3.0
Using digital models to evolve the form
of expression, of the vehicle for looking with intent — at models mental, physical, and digital — and showing that you did.
Not only a fusion, but an evolution in form that surfaces the best of both media (model and drawing), in a new form of expression greater than the sum of its parts.
From our blog
Our latest, running commentary

Looking with intent
and showing that you did
